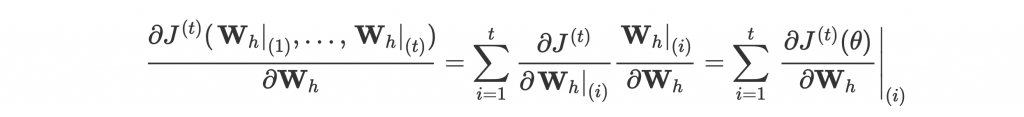Word vectors 是帶動 deep learning 在 NLP 發展的重要基礎。但有了 word vectors 作為文字的 features,接下來要用它來訓練一個成功的 neural network,可沒這麼簡單。
主要原因就是,文字不只局部,還需要有連貫性。
想像一個 Question Answering system(問答系統),data 大概類似:
Context:
Roger Federer is a Swiss professional tennis player who is ranked world No. 4 in men's singles tennis by the Association of Tennis Professionals (ATP). He has won 20 Grand Slam singles titles—the most in history for a male player—and has held the world No. 1 spot in the ATP rankings for a record total of 310 weeks (including a record 237 consecutive weeks) and was the year-end No. 1 five times, including four consecutive.
—— 取自 Wiki - Roger Federer
Q: How long is the longest total weeks at ATP No. 1 in history?
A: 310
Context 跟 Q 會是 input,要 predict 出 A。
如果用我們學到最一般的 fully-connected layer 來架構,那大概會長這樣:

這個架構最不現實的就是,input layer 不可能這樣固定大小!其他不同長度的文章會有不同 input size,難道要每種長度訓練一種 network?但文章長度沒有最長只有更長⋯⋯
既然用全文當 input 不可行,那你可能想說,好那用固定的 window 大小抓住局部訊息,每個局部預測答案,如果局部文字跟問題無關,就輸出 N/A,而當處理到能看出答案的局部文字,就預測答案。
不過這方法也不太可行。假設 window size 是 5 好了,每個 window 可能預測結果為:
| Window | 預測 |
|---|---|
| Roger Federer is a Swiss | N/A |
| Federer is a Swiss Tennis | N/A |
| ... | ... |
| No. 1 spot in the ATP | N/A |
| ... | ... |
| record total of 310 weeks | N/A |
| ... | ... |
咦不對啊,怎麼都是 N/A?因為雖然 "record total of 310 weeks" 包含答案,但因為沒有 ATP No.1 的訊息,network 也就不能很有信心的說 310 是問題的答案。而如果把 window size 調大或許能成功回答沒錯,但有時候一個問題的相關部分差距可以很遠,所以我們也永遠不可能讓 window size 夠大!
所以關鍵在於怎麼用一個固定大小的 layer 包含不同長度的文字所隱含的意義。這就是 RNN 能做到的事。
Recurrent Neural Network (RNN),中文稱循環神經網絡,目的在於學習與記憶時間相關的序列。
主要概念是把前一次學到的 hidden state 當作當前 hidden layer 的 input,再把 output 傳給下一次的 hidden layer,如此循環下去,每一輪都把前面學到的 feature 添加當前的 feature 傳遞下去,到文末的時候,就能獲得前面所有文字的記憶了。

—— A Recurrent Neural Network (RNN) node。[3]

—— RNN 架構。[1]
圖中我們把 input text 序列分成很多 timestep,每個 timestep t 輸入一個字 ,進入 hidden layer 產生 output
,也就是對下一個字的預測。這個 output 在訓練時用來取每一步的 loss,但在 evaluation 時我們通常要走完整個序列才能做預測,所以 final prediction 可能會在很右邊。前面這一層層循環我們稱為 encoding,也就是把資訊轉換成某個格式(這邊是 hidden state)的過程。
這個架構下的 weights W 每一輪都是相同的,也就是 parameters 數量不會跟著序列長度增加,這也是很好的消息。
我們來看個更完整的過程。假設在做 text generation(文字生成),那整個過程展開來,會如下圖:

—— Text generation 預測下個文字。[1]
第一層先取 word embedding e,再進入 RNN layer 進行 encoding,最後用 encode 完四個字的 hidden state 對下個字進行預測。
RNN 大致的架構大概懂了,我們來簡單看一下怎麼做訓練。
在每一個 timestep 的 loss 會是:

但特別的是不只當前的 parameters 會影響到這個 loss,前面所有 timestep 的 parameters 也都對 loss 有貢獻。所以雖然是同一組 parameters,我們還要計算在每個 timestep 的 gradient 並累加:

—— Backpropagation through time。[1]
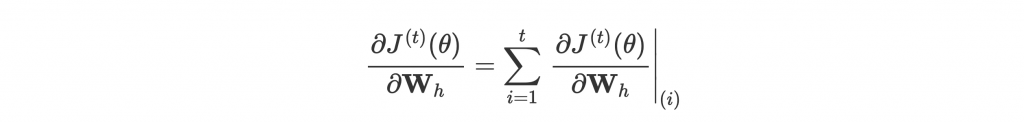
等式右邊是 在 timestep i 對
的 gradient。
運用 multivariable chain rule,可以得出:
Multivariable chain rule 請參考 [4]。
有了每個 timestep 的 gradient,就能計算平均 loss:
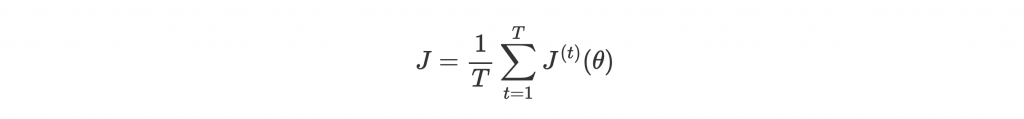
不過從尾巴一路 backpropagate 到頭,對很多 timestep 的 dataset 來說可能會太慢。所以通常會以小一點的 batch 或直接以 sentence 為單位當 T。
上面介紹最基本的 RNN,其實存在很多缺陷。最大的問題就是 vanishing gradient。
Vanishing gradient 簡單來說就是 gradient 越往前面 backpropagate,gradient 本身會越來越小,而前面的 timestep 就得不到太多的修正資訊。也就是說,RNN 會沒辦法記住太久遠以前的資訊。
下圖中,我們在 t = 4 計算對一開始 hidden layer 的 gradient:

—— 對久遠以前的 timestep 計算 gradient。[2]
可以發現如果框框中的值太小,那 gradient 也會被越乘越小。甚至只要他們小於 1,只要間隔 timestep 夠長,gradient 最終也會越來越接近 0。
這個致命的問題,也讓 RNN 的一些其他變形被提出。LSTM 和 GRU 就是很常使用的兩種變形。
Long Short-Term Memory (LSTM) 把每一層的運作變得複雜了一點:

—— LSTM 架構。[2]

—— 一個 LSTM cell。[2]
背後的數學原理不是要探討的重點。只需要知道 LSTM 內部除了 hidden state 還添加了 cell state 當作資訊庫,並建立了 forget gate 和 input gate 來控制哪些資訊要被遺忘或傳遞,還有 output gate 來決定資訊庫中的哪些資訊在當下最有用,要輸出給 hidden state。
而這些控制閥的計算方式,讓原本在 RNN 會趨近於 0 的 gradient 得以避免太靠近 0,也就是為什麼比較不會產生 vanishing gradient 的問題。
對這件事有興趣的可以參考 [5] 的解釋。
Gated Recurrent Unit (GRU) 原理和 LSTM 相似,但更簡單一些,因此速度更快,也更省空間。
GRU 沒有 cell state 只有 hidden state,先用 reset gate 來控制前一個 hidden state 有哪些部分可以利用來跟當前 input 得出新資訊,並用 update gate 來選擇怎麼整合前一個 hidden state 和這些新資訊。
LSTM 和 GRU 主要解決 vanishing gradient 的問題,而接下來要介紹的 bidirectional RNN 和 multi-layer RNN 則是增強了 RNN 捕捉的資訊。
有時候文字資訊的傳遞不只是由前往後,也可能由後往前!
舉個例子來說:
這間早餐店並不好吃,他好吃極了!
當一個 RNN model 處理到"不好吃",並不能學習到整句的全貌。但如果能加進由後往前的資訊,他就能馬上知道"不好吃"並不是真的不好吃。
Bidirectional RNN 目的就是為了捕捉由後往前的資訊。方法很簡單,就是再加一層由後往前的 backward RNN layer:

—— Bidirectional RNN 架構。[2]
並把 forward 和 backward RNN 得到的 hidden state 合併在一起,當作當前的 hidden state。
跟 deep learning 加層的概念一樣,我們當然也能替 RNN 加更多層來學習不同層次的 feature。這就是 multi-layer RNN。

—— Multi-layer RNN 架構。[2]
Day 5 的時候有提到自己 PyTorch 的第一個 project,將《論語》和《毛澤東語錄》混在一起做 Chinese text generation。訓練得雖然不是很好,但架構簡易,不如用來示範怎麼使用 RNN。
原始版在這裡,還有附完整介紹文。這邊我們稍微修一下 code,然後簡單看一下 model 怎麼建立就好。新的 code 放在 GitHub:pyliaorachel/knock-knock-deep-learning,其他沒提到的部分想知道可以參考。
這個 project 裡,我們讓 input 為長度 50 的句子,並預測這句後面出現的下一個字。架構是最基本的 embedding、LSTM layer、fully-connected layer:
class Net(nn.Module):
def __init__(self, n_vocab, embedding_dim, hidden_dim, dropout=0.2):
super(Net, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(n_vocab, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=2, dropout=dropout)
self.hidden2out = nn.Linear(hidden_dim, n_vocab)
def forward(self, seq_in):
embeddings = self.embeddings(seq_in.t()) # LSTM takes 3D inputs (timesteps, batch, features)
# = (seq_length, batch_size, embedding_dim)
lstm_out, _ = self.lstm(embeddings) # Each timestep outputs 1 hidden_state
# Combined in lstm_out = (seq_length, batch_size, hidden_dim)
ht = lstm_out[-1] # ht = last hidden state = (batch_size, hidden_dim)
# Use the last hidden state to predict the following character
out = self.hidden2out(ht) # Fully-connected layer, predict (batch_size, n_vocab)
return out
在傳遞 data 的時候,要注意 input 的形狀要求,以及 input dimension 的意義。這邊 LSTM 要求 input 是 (seq_len, batch, input_size),如果對 RNN 還不夠熟悉的可能會混淆 seq_len 和 input_size。Input 是每個 timestep 的 input,所以等於 embedding size,初學者可能以為是輸入句子的長度。seq_len 才是句子的長度,因為句子是字的序列。
我們給他 train 30 個 epoch,看看結果。
首先是每個 epoch 的平均 training loss:

—— Average training loss over epochs。
看起來是還沒有收斂,但還可以。我們另外分了兩成的 data 作為 test set,計算平均 test loss 為 $4.66$。
最後還寫了 gen.py 來生成句子,用肉眼來檢視結果。這邊值得一提的是選擇 prediction 的時候,並不是挑 probability 最高的字當作下一個字,因為這樣做的話,會發現因為機率最高的字都差不多,而一直產生重複的字。
所以 prediction 要根據 output probability 當作機率分佈選字。Output 假設是 ['你': 0.3, '好': 0.1, '嗎': 0.6],那麼"嗎"就只有 6 成機會被選中,而不是永遠都選他。
Code 是這麼寫:
pred = model(seq_in)
prob = F.softmax(pred, dim=1)[0] # batch size 是 1,直接取第一組
char = np.random.choice(dataset.chars, p=prob.numpy())
我們來生成幾組句子試試看:
人,不是自然的人,我说话称赞了自由精神。现在的一切工作,
虽然也没有领导的政治实经上。君子具有三种优方法,
不维足端物地有到了,起坚变完了,也就会成刑功变。
这不是老师,那是谁啊?老人求到得实践市意恰。却无事坏事鬼得呀!
这里都乱了。有文重的人交官位却不违罢,
而些:君子请父杀了国家的财论,就应该像合起来。
孔子长,一样做地方,这就是保走人。这种朋索又需要在大长。
子有利召啊!一种人面赞妄八理的人交翼,是他对于人民的微风界占物论方法。
一般由于自己的革命有马(不将也最后力量,而上作手批评问题,这是对于思想。
现在还要地方内部求关系,凡是科学别的教育,
常服党计划的勇气兼长行动理动势分挥指导了理风及不些行,
不同地那限整个共产党员,必须爱重干部也愿民主的精神,在外起来,
我们就必打和批评。这个人很关个受有的,不是创造的余对说一一方面,
一座或礼成或修养地位去来说,不用。自己是在石政党领导,好比二受中国,
最到个人的经计人好力而像(革命所有地进攻的阶级,
任何其式官兵我们的矛盾,这就是属于党委的方法。我们同志的据点,
就不较深采的领导者为进了观极农民的民主义走到打仗迅革命运配以垮农合起来,
摆到用一切行反动派来作变为了我们的领导。
我们不能作为起来虽然我很百地时一定会改变仁德的道德。孝守信啊,
才能立它出发,而立出后一执的规面都是万先的正确。
说的是说话的,只是不远却实行仁德的方法去。
可以看到雖然詞不達意,但學到了很多經典詞:毛澤東語錄的共產黨員、領導,和論語的君子、仁德等等。還有一些文法:"這不是老師,那是誰啊?"、"這就是屬於黨委的方法"等等。
整體來說有接近自然語言的趨勢,若再加強 model 例如加入 pre-trained character embedding、attention 等等,並訓練久一點,效果應該能更好。
我們從 RNN 的 motivation 和架構介紹起,並解釋了他的缺點和改善之後的幾個變形架構,最後介紹了自己新手時期的中文生成 project。
RNN 算是做 NLP 最簡易的入門,但之後會再介紹的 transformer 可以達到更好的 performance,也是現在主流的架構。